
Leader Election Pattern in Java: Mastering Node Coordination and Consensus
Also known as
- Coordinator Election
- Master Election
Intent of Leader Election Design Pattern
The Leader Election design pattern is crucial for enabling a system to elect a leader from a group of nodes, ensuring the leader is consistently recognized and able to coordinate tasks while other nodes remain followers. This pattern is fundamental in distributed systems, particularly for achieving fault tolerance and high availability.
Detailed Explanation of Leader Election Pattern with Real-World Examples
Real-world example
A real-world analogy to the Leader Election pattern is the election of a team captain in sports. All team members (nodes) participate in the election process, following a set of agreed-upon rules (protocol). Once a captain (leader) is chosen, they assume responsibility for coordinating strategies, giving directions, and representing the team in discussions. If the captain is injured or unavailable, the team holds a new election or appoints a vice-captain (failover mechanism) to ensure that leadership and direction are maintained consistently.
In plain words
The leader election pattern is a design approach that enables a distributed system to select one node as the coordinator or leader to manage tasks and maintain order, while other nodes operate as followers.
Wikipedia says
In distributed computing, leader election is the process of designating a single process as the organizer of some task distributed among several computers (nodes). Before the task has begun, all network nodes are either unaware which node will serve as the "leader" (or coordinator) of the task, or unable to communicate with the current coordinator. After a leader election algorithm has been run, however, each node throughout the network recognizes a particular, unique node as the task leader.
Sequence diagram
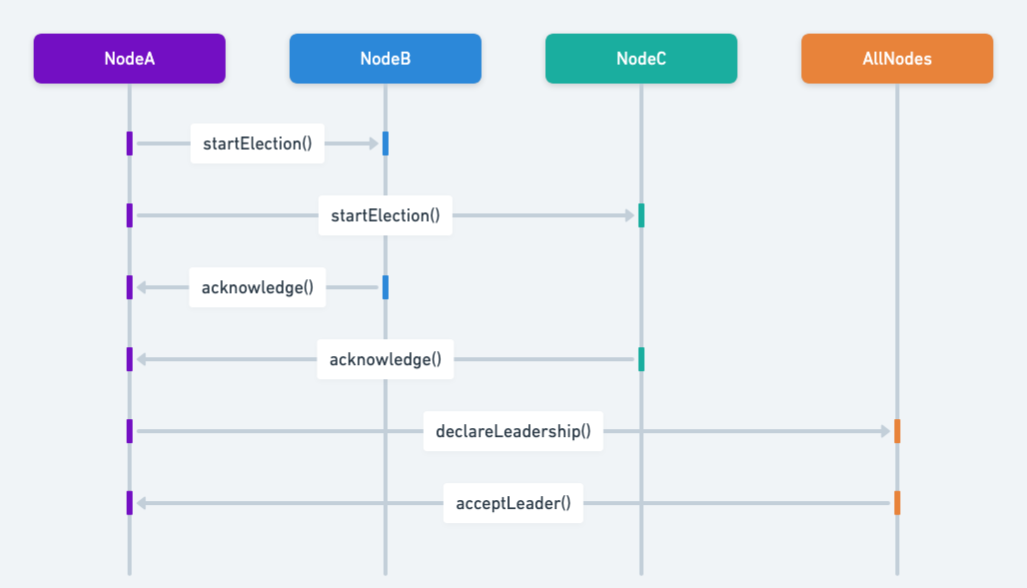
Programmatic Example of Leader Election Pattern in Java
The Leader Election pattern is a design approach that enables a distributed system to select one node as the coordinator or leader to manage tasks and maintain order, while other nodes operate as followers. This pattern is particularly useful in distributed systems where one node needs to act as a central coordinator for a specific function or decision-making process.
In the provided code, we have an AbstractMessageManager class and AbstractInstance class. The AbstractMessageManager class is responsible for managing messages between instances and finding the next instance (potential leader) based on certain conditions. The AbstractInstance class represents a node in the distributed system.
Let's break down the code and explain how it works:
public abstract class AbstractMessageManager implements MessageManager {
protected Map<Integer, Instance> instanceMap;
public AbstractMessageManager(Map<Integer, Instance> instanceMap) {
this.instanceMap = instanceMap;
}
protected Instance findNextInstance(int currentId) {
// Implementation details...
}
}The AbstractMessageManager class manages the instances in the system. It contains a map of instances, where the key is the instance ID and the value is the instance itself. The findNextInstance method is used to find the next instance with the smallest ID that is alive. This method can be used in the leader election process to determine the next leader if the current leader fails.
public abstract class AbstractInstance implements Instance {
protected int id;
protected boolean alive;
protected MessageManager messageManager;
public AbstractInstance(MessageManager messageManager, int id) {
this.messageManager = messageManager;
this.id = id;
this.alive = true;
}
public boolean isAlive() {
return alive;
}
public void setAlive(boolean alive) {
this.alive = alive;
}
public void onMessage(Message message) {
// Implementation details...
}
}The AbstractInstance class represents a node in the distributed system. Each instance can check if it's alive, set its health status, and consume messages from other instances.
Now, let's look at the BullyApp and RingApp classes, which implement two different leader election algorithms:
public class BullyApp {
public static void main(String[] args) {
Map<Integer, Instance> instanceMap = new HashMap<>();
var messageManager = new BullyMessageManager(instanceMap);
var instance1 = new BullyInstance(messageManager, 1, 1);
// ... more instances ...
instanceMap.put(1, instance1);
// ... more instances ...
instance1.setAlive(false);
}
}The BullyApp class implements the Bully algorithm for leader election. In this algorithm, when a node notices the leader is down, it starts an election by sending an election message to all nodes with higher IDs. If it doesn't receive a response, it declares itself the leader and sends a victory message to all nodes with lower IDs.
public class RingApp {
public static void main(String[] args) {
Map<Integer, Instance> instanceMap = new HashMap<>();
var messageManager = new RingMessageManager(instanceMap);
var instance1 = new RingInstance(messageManager, 1, 1);
// ... more instances ...
instanceMap.put(1, instance1);
// ... more instances ...
instance1.setAlive(false);
}
}The RingApp class implements the Ring algorithm for leader election. In this algorithm, each node sends an election message to its neighbor in a logical ring topology. When a node receives an election message, it passes it on if the ID in the message is higher than its own. The process continues until the message has made a full circle, at which point the node with the highest ID becomes the leader.
These examples demonstrate how the Leader Election pattern can be implemented in different ways to suit the specific requirements of a distributed system.
When to Use the Leader Election Pattern in Java
Use the Leader Election pattern in Java applications where:
- A distributed system needs one node to act as the central coordinator for a specific function or decision-making process.
- High availability is essential, and the leader should be replaceable in case of failure.
- Coordination is required across different nodes in a cluster, particularly in cloud environments.
Real-World Applications of Leader Election Pattern in Java
- Apache ZooKeeper: Provides leader election for distributed services.
- Kubernetes: Elects a leader pod to manage stateful workloads.
- Hazelcast: Distributed data grid uses leader election for cluster management.
Benefits and Trade-offs of Leader Election Pattern
Benefits:
- Consistency: Ensures a single, consistent leader handles coordination tasks.
- Fault Tolerance: Allows for leader replacement if the current leader fails.
- Scalability: Works effectively in large, distributed systems where multiple nodes are present.
Trade-offs:
- Complexity: Requires careful implementation to handle network partitions and latency.
- Overhead: Election processes may introduce performance overhead.
- Single Point of Failure: Even with redundancy, the leader can become a bottleneck if not carefully designed.
Related Java Design Patterns
- Observer: Followers can observe changes from the leader to stay updated.
- Singleton: The leader functions as a single instance, acting as a unique decision-maker.
- State: Helps in managing state transitions, particularly in switching leadership roles.