
Sharding Pattern in Java: Mastering Horizontal Partitioning to Boost Application Throughput
Also known as
- Data Partitioning
- Horizontal Partitioning
Intent of Sharding Design Pattern
Sharding, a pivotal Java design pattern, significantly boosts database scalability and performance through horizontal partitioning.
Detailed Explanation of Sharding Pattern with Real-World Examples
Real-world example
Consider a large e-commerce website with millions of users and transactions. To handle the immense amount of data and ensure the system remains responsive, the user data is sharded across multiple database servers. For instance, users with IDs ending in 0-4 might be stored on one server, and those ending in 5-9 on another. This distribution allows the system to handle a higher load by parallelizing read and write operations across multiple servers.
In plain words
Separates the processing logic from the view in web applications to improve maintainability and scalability.
Wikipedia says
Horizontal partitioning is a database design principle whereby rows of a database table are held separately, rather than being split into columns (which is what normalization and vertical partitioning do, to differing extents). Each partition forms part of a shard, which may in turn be located on a separate database server or physical location.
There are numerous advantages to the horizontal partitioning approach. Since the tables are divided and distributed into multiple servers, the total number of rows in each table in each database is reduced. This reduces index size, which generally improves search performance. A database shard can be placed on separate hardware, and multiple shards can be placed on multiple machines. This enables a distribution of the database over a large number of machines, greatly improving performance. In addition, if the database shard is based on some real-world segmentation of the data (e.g., European customers v. American customers) then it may be possible to infer the appropriate shard membership easily and automatically, and query only the relevant shard.
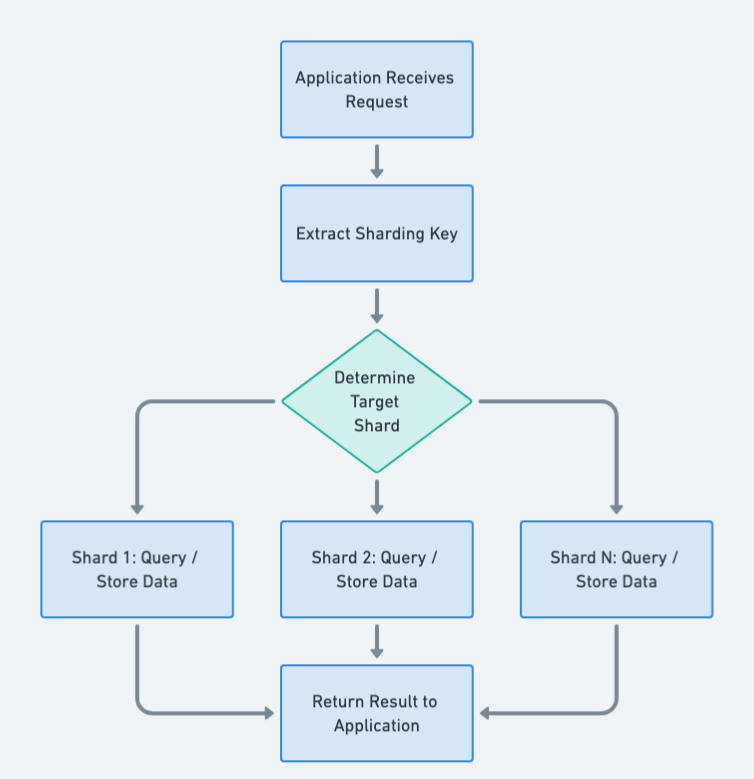
Flowchart
Programmatic Example of Sharding Pattern in Java
Sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small part of a whole. In software architecture, it refers to a horizontal partition in a database or search engine. Each individual partition is referred to as a shard or database shard.
In the given code, we have a ShardManager class that manages the shards. It has two subclasses HashShardManager and RangeShardManager that implement different sharding strategies. The Shard class represents a shard that stores data. The Data class represents the data to be stored in the shards.
The ShardManager is an abstract class that provides the basic structure for managing shards. It has a storeData method that stores data in a shard and an allocateShard method that determines which shard to store the data in. The allocateShard method is abstract and must be implemented by subclasses.
public abstract class ShardManager {
protected Map<Integer, Shard> shardMap = new HashMap<>();
public abstract int storeData(Data data);
protected abstract int allocateShard(Data data);
}The HashShardManager is a subclass of ShardManager that implements a hash-based sharding strategy. In the allocateShard method, it calculates a hash of the data key and uses it to determine the shard to store the data in.
public class HashShardManager extends ShardManager {
@Override
protected int allocateShard(Data data) {
var shardCount = shardMap.size();
var hash = data.getKey() % shardCount;
return hash == 0 ? hash + shardCount : hash;
}
}The RangeShardManager is another subclass of ShardManager that implements a range-based sharding strategy. In the allocateShard method, it uses the data type to determine the shard to store the data in.
public class RangeShardManager extends ShardManager {
@Override
protected int allocateShard(Data data) {
var type = data.getType();
return switch (type) {
case TYPE_1 -> 1;
case TYPE_2 -> 2;
case TYPE_3 -> 3;
};
}
}The Shard class represents a shard. It has a storeData method that stores data in the shard and a getDataById method that retrieves data from the shard by its id.
public class Shard {
@Getter
private final int id;
private final Map<Integer, Data> dataStore;
public Shard(final int id) {
this.id = id;
this.dataStore = new HashMap<>();
}
public void storeData(Data data) {
dataStore.put(data.getKey(), data);
}
public Data getDataById(final int id) {
return dataStore.get(id);
}
}The Data class represents the data to be stored in the shards. It has a key, a value, and a type.
@Getter
@Setter
public class Data {
private int key;
private String value;
private DataType type;
public Data(final int key, final String value, final DataType type) {
this.key = key;
this.value = value;
this.type = type;
}
enum DataType {
TYPE_1, TYPE_2, TYPE_3
}
}This is the main function of the example demonstrating three different sharding strategies: lookup, range, and hash. Each strategy determines which shard to store the data in a different way. The lookup strategy uses a lookup table, the range strategy uses the data type, and the hash strategy uses a hash of the data key.
public static void main(String[] args) {
var data1 = new Data(1, "data1", Data.DataType.TYPE_1);
var data2 = new Data(2, "data2", Data.DataType.TYPE_2);
var data3 = new Data(3, "data3", Data.DataType.TYPE_3);
var data4 = new Data(4, "data4", Data.DataType.TYPE_1);
var shard1 = new Shard(1);
var shard2 = new Shard(2);
var shard3 = new Shard(3);
var manager = new LookupShardManager();
manager.addNewShard(shard1);
manager.addNewShard(shard2);
manager.addNewShard(shard3);
manager.storeData(data1);
manager.storeData(data2);
manager.storeData(data3);
manager.storeData(data4);
shard1.clearData();
shard2.clearData();
shard3.clearData();
var rangeShardManager = new RangeShardManager();
rangeShardManager.addNewShard(shard1);
rangeShardManager.addNewShard(shard2);
rangeShardManager.addNewShard(shard3);
rangeShardManager.storeData(data1);
rangeShardManager.storeData(data2);
rangeShardManager.storeData(data3);
rangeShardManager.storeData(data4);
shard1.clearData();
shard2.clearData();
shard3.clearData();
var hashShardManager = new HashShardManager();
hashShardManager.addNewShard(shard1);
hashShardManager.addNewShard(shard2);
hashShardManager.addNewShard(shard3);
hashShardManager.storeData(data1);
hashShardManager.storeData(data2);
hashShardManager.storeData(data3);
hashShardManager.storeData(data4);
shard1.clearData();
shard2.clearData();
shard3.clearData();
}Finally, here is the program output:
18:32:26.503 [main] INFO com.iluwatar.sharding.LookupShardManager -- Data {key=1, value='data1', type=TYPE_1} is stored in Shard 2
18:32:26.505 [main] INFO com.iluwatar.sharding.LookupShardManager -- Data {key=2, value='data2', type=TYPE_2} is stored in Shard 2
18:32:26.505 [main] INFO com.iluwatar.sharding.LookupShardManager -- Data {key=3, value='data3', type=TYPE_3} is stored in Shard 1
18:32:26.505 [main] INFO com.iluwatar.sharding.LookupShardManager -- Data {key=4, value='data4', type=TYPE_1} is stored in Shard 1
18:32:26.506 [main] INFO com.iluwatar.sharding.RangeShardManager -- Data {key=1, value='data1', type=TYPE_1} is stored in Shard 1
18:32:26.506 [main] INFO com.iluwatar.sharding.RangeShardManager -- Data {key=2, value='data2', type=TYPE_2} is stored in Shard 2
18:32:26.506 [main] INFO com.iluwatar.sharding.RangeShardManager -- Data {key=3, value='data3', type=TYPE_3} is stored in Shard 3
18:32:26.506 [main] INFO com.iluwatar.sharding.RangeShardManager -- Data {key=4, value='data4', type=TYPE_1} is stored in Shard 1
18:32:26.506 [main] INFO com.iluwatar.sharding.HashShardManager -- Data {key=1, value='data1', type=TYPE_1} is stored in Shard 1
18:32:26.506 [main] INFO com.iluwatar.sharding.HashShardManager -- Data {key=2, value='data2', type=TYPE_2} is stored in Shard 2
18:32:26.506 [main] INFO com.iluwatar.sharding.HashShardManager -- Data {key=3, value='data3', type=TYPE_3} is stored in Shard 3
18:32:26.506 [main] INFO com.iluwatar.sharding.HashShardManager -- Data {key=4, value='data4', type=TYPE_1} is stored in Shard 1When to Use the Sharding Pattern in Java
- Use when dealing with large datasets that exceed the capacity of a single database.
- Ideal for Java applications requiring robust scalability, sharding improves performance by distributing database loads effectively.
- Useful for applications requiring high availability and fault tolerance.
- Effective in environments where read and write operations can be parallelized across shards.
Real-World Applications of Sharding Pattern in Java
- Distributed databases such as Apache Cassandra, MongoDB, and Amazon DynamoDB.
- Large-scale web applications like social networks, e-commerce platforms, and SaaS products.
Benefits and Trade-offs of Sharding Pattern
Benefits:
- Enhances performance by distributing load.
- Improves scalability by allowing horizontal scaling.
- Increases availability and fault tolerance by isolating failures to individual shards.
Trade-offs:
- Complexity in managing and maintaining multiple shards.
- Potential challenges in rebalancing shards as data grows.
- Increased latency for cross-shard queries.
Related Java Design Patterns
- Caching: Can be used in conjunction with sharding to further improve performance.
- Data Mapper: Helps in abstracting and encapsulating the details of database interactions, which can be complex in a sharded environment.
- Repository: Provides a way to manage data access logic centrally, which is useful when dealing with multiple shards.
- Service Locator: Can be used to find and interact with different shards in a distributed system.
References and Credits
- Building Scalable Web Sites: Building, Scaling, and Optimizing the Next Generation of Web Applications
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence
- Sharding pattern (Microsoft)