
Retry Pattern in Java: Building Fault-Tolerant Systems with Adaptive Retries
Also known as
- Retry Logic
- Retry Mechanism
Intent of Retry Design Pattern
The Retry pattern in Java transparently retries certain operations that involve communication with external resources, particularly over the network, isolating calling code from the retry implementation details. It is crucial for developing resilient software systems that handle transient failures gracefully.
Detailed Explanation of Retry Pattern with Real-World Examples
Real-world example
Imagine you're a delivery driver attempting to deliver a package to a customer's house. You ring the doorbell, but no one answers. Instead of leaving immediately, you wait for a few minutes and try again, repeating this process a few times. This is similar to the Retry pattern in software, where a system retries a failed operation (e.g., making a network request) a certain number of times before finally giving up, in hopes that the issue (e.g., transient network glitch) will be resolved and the operation will succeed.
In plain words
Retry pattern transparently retries failed operations over network.
Enable an application to handle transient failures when it tries to connect to a service or network resource, by transparently retrying a failed operation. This can improve the stability of the application.
Flowchart
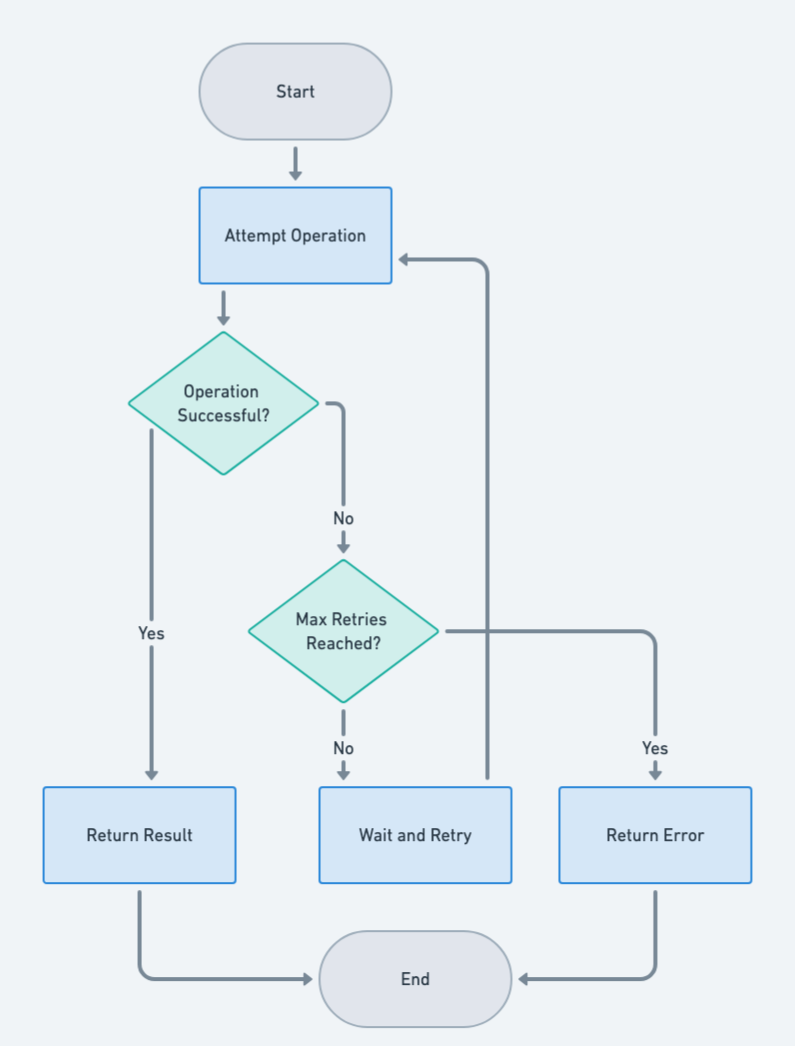
Programmatic Example of Retry Pattern in Java
The Retry design pattern is a resilience pattern that allows an application to transparently attempt to execute operations multiple times in the expectation that it'll succeed. This pattern is particularly useful when the application is connecting to a network service or a remote resource, where temporary failures are common.
First, we have a BusinessOperation interface that represents an operation that can be performed and might throw a BusinessException.
public interface BusinessOperation<T> {
T perform() throws BusinessException;
}Next, we have a FindCustomer class that implements this interface. This class simulates a flaky service that intermittently fails by throwing BusinessExceptions before eventually returning a customer's ID.
public final class FindCustomer implements BusinessOperation<String> {
@Override
public String perform() throws BusinessException {
// ...
}
}The Retry class is where the Retry pattern is implemented. It takes a BusinessOperation and a number of attempts, and it will keep trying to perform the operation until it either succeeds or the maximum number of attempts is reached.
public final class Retry<T> implements BusinessOperation<T> {
private final BusinessOperation<T> op;
private final int maxAttempts;
private final long delay;
private final AtomicInteger attempts;
private final Predicate<Exception> test;
private final List<Exception> errors;
@SafeVarargs
public Retry(
BusinessOperation<T> op,
int maxAttempts,
long delay,
Predicate<Exception>... ignoreTests
) {
this.op = op;
this.maxAttempts = maxAttempts;
this.delay = delay;
this.attempts = new AtomicInteger();
this.test = Arrays.stream(ignoreTests).reduce(Predicate::or).orElse(e -> false);
this.errors = new ArrayList<>();
}
public List<Exception> errors() {
return Collections.unmodifiableList(this.errors);
}
public int attempts() {
return this.attempts.intValue();
}
@Override
public T perform() throws BusinessException {
do {
try {
return this.op.perform();
} catch (BusinessException e) {
this.errors.add(e);
if (this.attempts.incrementAndGet() >= this.maxAttempts || !this.test.test(e)) {
throw e;
}
try {
Thread.sleep(this.delay);
} catch (InterruptedException f) {
//ignore
}
}
} while (true);
}
}In this class, the perform method tries to perform the operation. If the operation throws an exception, it checks if the exception is recoverable and if the maximum number of attempts has not been reached. If both conditions are true, it waits for a specified delay and then tries again. If the exception is not recoverable or the maximum number of attempts has been reached, it rethrows the exception.
Finally, here is the App class driving the retry pattern example.
public final class App {
private static final Logger LOG = LoggerFactory.getLogger(App.class);
public static final String NOT_FOUND = "not found";
private static BusinessOperation<String> op;
public static void main(String[] args) throws Exception {
noErrors();
errorNoRetry();
errorWithRetry();
errorWithRetryExponentialBackoff();
}
private static void noErrors() throws Exception {
op = new FindCustomer("123");
op.perform();
LOG.info("Sometimes the operation executes with no errors.");
}
private static void errorNoRetry() throws Exception {
op = new FindCustomer("123", new CustomerNotFoundException(NOT_FOUND));
try {
op.perform();
} catch (CustomerNotFoundException e) {
LOG.info("Yet the operation will throw an error every once in a while.");
}
}
private static void errorWithRetry() throws Exception {
final var retry = new Retry<>(
new FindCustomer("123", new CustomerNotFoundException(NOT_FOUND)),
3, //3 attempts
100, //100 ms delay between attempts
e -> CustomerNotFoundException.class.isAssignableFrom(e.getClass())
);
op = retry;
final var customerId = op.perform();
LOG.info(String.format(
"However, retrying the operation while ignoring a recoverable error will eventually yield "
+ "the result %s after a number of attempts %s", customerId, retry.attempts()
));
}
private static void errorWithRetryExponentialBackoff() throws Exception {
final var retry = new RetryExponentialBackoff<>(
new FindCustomer("123", new CustomerNotFoundException(NOT_FOUND)),
6, //6 attempts
30000, //30 s max delay between attempts
e -> CustomerNotFoundException.class.isAssignableFrom(e.getClass())
);
op = retry;
final var customerId = op.perform();
LOG.info(String.format(
"However, retrying the operation while ignoring a recoverable error will eventually yield "
+ "the result %s after a number of attempts %s", customerId, retry.attempts()
));
}
}Running the code produces the following console output.
10:12:19.573 [main] INFO com.iluwatar.retry.App -- Sometimes the operation executes with no errors.
10:12:19.575 [main] INFO com.iluwatar.retry.App -- Yet the operation will throw an error every once in a while.
10:12:19.682 [main] INFO com.iluwatar.retry.App -- However, retrying the operation while ignoring a recoverable error will eventually yield the result 123 after a number of attempts 1
10:12:22.297 [main] INFO com.iluwatar.retry.App -- However, retrying the operation while ignoring a recoverable error will eventually yield the result 123 after a number of attempts 1This way, the Retry pattern allows the application to handle temporary failures gracefully, improving its resilience and reliability.
When to Use the Retry Pattern in Java
Applying the Retry pattern is particularly effective
- When operations can fail transiently, such as network calls, database connections, or external service integrations.
- In scenarios where the likelihood of transient failure is high but the cost of retries is low.
Real-World Applications of Retry Pattern in Java
- In network communication libraries to handle transient failures.
- Database connection libraries to manage temporary outages or timeouts.
- APIs interacting with third-party services that may be temporarily unavailable.
Benefits and Trade-offs of Retry Pattern
Benefits:
- Increases the robustness and fault tolerance of applications.
- Can significantly reduce the impact of transient failures.
Trade-offs:
- May introduce latency due to retries.
- Can lead to resource exhaustion if not managed properly.
- Requires careful configuration of retry parameters to avoid exacerbating the problem.
Related Java Design Patterns
- Circuit Breaker: Used to stop the flow of requests to an external service after a failure threshold is reached, preventing system overload.